The 3.2% Problem: what's holding back the world's most powerful computers
- Thomas Thurston

- Apr 29
- 6 min read
Here's a number that surprised us: 3.2%.
We recently mapped nearly 1,000 technologies involved in combining the world's biggest computers with the world's most sophisticated artificial intelligence. We expected to find a hardware story. We found something else entirely.
Two kinds of computing, learning to work together
Most people have heard of AI. Fewer have heard of high performance computing, or HPC.
Think of HPC as brute-force precision. When engineers simulate whether a bridge will survive an earthquake, or when climate scientists model how the atmosphere behaves over decades, they're using HPC. These machines solve enormous equations, step by step, with extraordinary accuracy. They're the biggest, most expensive computers on Earth, often filling entire buildings.
AI works differently. Instead of solving one giant equation precisely, AI processes millions of small calculations simultaneously, looking for patterns. It's less precise, but it's fast, and it's surprisingly good at approximation.
For most of their history, these two worlds operated separately. HPC lived in national labs and universities. AI lived in tech companies and startups. They spoke different languages, used different hardware, solved different problems.
That's changing. People figured out that combining them could unlock something neither could do alone. Let AI learn from HPC simulations and then approximate the results thousands of times faster, and you could model things that were previously impossible. A climate model that takes weeks to run could be approximated in minutes. A drug interaction simulation that tests one molecule at a time could explore thousands simultaneously. A structural engineering analysis that evaluates one design could evaluate ten thousand.
What we set out to learn
My team uses computation to simulate how competitive markets evolve. We're not a national lab. We're not a tech company. We use models to inform decisions involving real money, and those models have to be right, not just fast.
We wanted to understand when we could build on HPC-AI infrastructure. What's ready? What's in the way?
So we did something unusual. We mapped 994 technologies across 7 overlapping value chains that make up the HPC-AI convergence for scientific computing. For each technology, we classified the supply-demand balance (is there enough of it?), the competitive landscape (how many companies supply it?) and how long each bottleneck is likely to persist.
Then we added a dimension most analyses miss. For each technology, we also asked: even if supply exists, what else prevents people from actually using it? We called these "adoption barriers." Things like validation requirements, licensing restrictions and integration challenges.

The hardware story (3.2% of the problem)
Start with what we expected. About 30% of the technologies are supply-constrained. Memory chips are tight. Advanced packaging is scarce. A handful of companies (you've heard of NVIDIA) dominate critical chokepoints. This is the story you read in the news. It's real.
When we crossed the supply-demand analysis with the adoption-barrier analysis, we found that only 32 of 994 technologies, a mere 3.2%, have a supply problem and nothing else. For those 32, if the factory ramped production, the technology would flow into use.
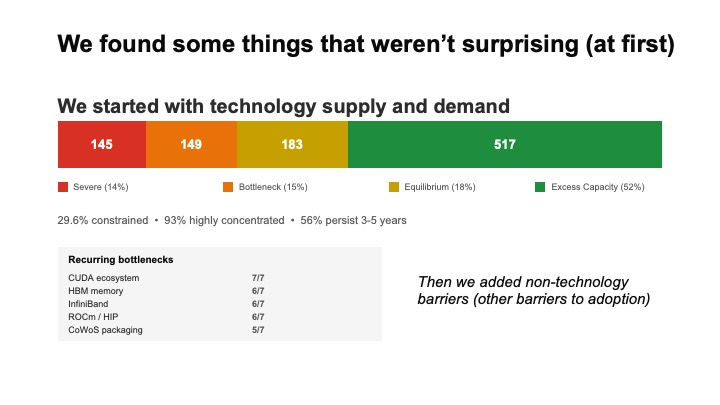
For the other 96.8%, something else is in the way. Even if every hardware shortage resolved tomorrow, most of these technologies would still be stuck.
What's actually in the way
The largest category of adoption barrier, at 34%, is scientific trust and validation. The core question isn't "can we build it?" or "can we buy it?" It's "can we prove this gives the right answer?"

To get a sense of the scale of this problem, think about something most people already understand: AI hallucinations. If you type something into ChatGPT and get the wrong answer, there’s a decent chance you’ll notice, you try again, you move on. The stakes on any single query are low, and you're the validator.
Now imagine a different scenario. Instead of one chat at a time, imagine a single computation that performs a quintillion calculations per second (that's a 1 followed by 18 zeros), runs continuously for months, and produces one answer at the end. Every calculation depends on the one before it. Errors don't announce themselves; they compound silently. Also imagine the answer is a prediction about the future state of the Earth's climate, or the structural integrity of a reactor, or the trajectory of a hurricane. You can't check it against reality because reality hasn't happened yet. That's what an exascale scientific simulation looks like. The trust problem isn't "did this one response hallucinate?" It's "did any of a quintillion interdependent calculations drift in a way that corrupted the final answer, and how would we even know?"
Trust and validation is bigger than integration challenges (28%), bigger than platform qualification (17%), bigger than regulatory barriers (8%). When you add up every barrier that mentions trust, validation, qualification or verification, it's 67% of all adoption barriers in the dataset.
Here's an example that makes this concrete. The American Society of Mechanical Engineers (ASME) started a committee in 2001 to develop standards for verifying and validating computer simulations. They work on whether or not users can trust classic HPC systems. ASME published its first terminology standard 2022. In other words, it took 21 years just to agree on what the words mean. Not to solve the problem. To define it.

The committee working on the same questions for AI and machine learning models hasn’t published yet. Do we have to wait two decades for that too?
The good news (and the catch)
There's a hopeful finding buried in the data. Of the 658 technologies that have adoption barriers but no supply constraint, 97% are likely to resolve within a year. These are real friction points: a software library that needs one more release cycle, a container runtime that needs a configuration update.
The catch is what's left after the easy barriers clear.
262 technologies, 26.4% of the total, have both supply constraints and adoption barriers simultaneously. We started calling these compound constraints. They take the longest to resolve because both technology and non-technology barriers are in the way. The supply side (manufacturing ramps, capacity expansions) typically resolves in 1-3 years. The adoption side (validation, qualification, trust-building) takes at least an estimated 5-10 years, or more.
When we projected the timeline forward: In 2026, the landscape looks like a wall of nearly 1,000 stuck technologies. By 2027, 682 have cleared, almost all adoption-barrier-only. What's left is a much smaller set, but almost entirely compound. By 2030, 66 remain, 82% compound. By 2034, only 13 technologies are still stuck. Every single one has both a supply constraint and an adoption barrier. Some, like the licensing terms that prevent researchers from freely sharing their software toolchains, may never resolve through normal market dynamics.

When is it "good enough"?
The system doesn't need all 994 technologies to be unblocked before it works. We identified 59 technologies on the critical path: the ones the entire infrastructure can't function without. About 80% of those resolve by 2030. That's the "good enough" threshold.
The last 20% is a different kind of problem. Those 10 technologies are all compound. They include things like power transformers for datacenters, validation pipelines for AI-generated scientific results and GPU software licensing restrictions. The supply side of each will resolve through manufacturing. The adoption side requires standards development, licensing changes or the kind of cross-industry agreement that markets alone won't deliver.
Why this matters beyond computing
The trust problem isn't unique to HPC or AI. It shows up everywhere people build models that inform consequential decisions.
In banking, nobody has ever told me the bottleneck is that Excel runs too slowly. The bottleneck is always proving the model gives defensible answers. In weather forecasting, it took roughly 60 years to go from "we can run a numerical weather model" to "we trust it enough to evacuate a city." The computation got faster by a factor of billions during that period. The trust-building happened on a human timescale.
The HPC-AI convergence is at the beginning of the same journey. The machines are getting faster every year. The process of proving they give the right answers isn't getting faster. Every hardware improvement makes the trust gap more visible, not less. The better the machine, the more conspicuous the question: can we trust what it tells us?
Here's one way to think about it: Amdahl's Law applied to institutions rather than code. Hardware is the parallel fraction: throw more resources at it and it speeds up. Trust is the serial fraction: it happens one validation at a time, one institution at a time, one domain at a time. It doesn't parallelize with more GPUs.
What comes next
This month we shared these results at the HPC-AI Advisory Council Swiss Conference in Locarno. Standing in front of the people who build and operate the world's fastest computers, we made three requests.
First, help us prove the answers are right. Build validation frameworks that work across domains, not just physics. The standards bodies are working on it, but the faster those standards ship, the faster everyone can build.
Second, make this infrastructure accessible. Right now, the kind of computing we're describing is practically available only to governments and the largest technology companies. Commercial users with real problems and real budgets are locked out. That leaves money on the table for both sides.
Third, give us a stack we can own, reproduce and audit. If we can't reproduce our results, our regulators won't accept them. No single vendor should be able to hold a simulation pipeline hostage through licensing terms.
These aren't requests for faster hardware. These are requests for infrastructure we can trust, reach and own. The HPC and AI communities have built the fastest machines in history. We're ready to use them. The real question is whether we can trust the answers.



